Data processing and EDA
Contents
This section includes and overview of the data processing steps performed on the datasets obtained from the ADNI database as well as Exploratory Data Analysis (EDA) to describe key trends in the data and to inform the modeling performed in the later sections of the report.
Data processing
Data sources
The data required for this work were drawn from multiple datasets, all obtained from the website of the Laboratory of Neuro Imaging (LONI) at the University of Southern California (USC). The data sets contained data from all three ADNI studies, but we restricted our usage to only ADNI1. The following datasets
Dataset merging & processing
The main dataset (ADNIMERGE), downloaded from the “study data” section, contains observations representing individual visits by subjects. Most columns represent a single biomarker. Some important columns are a unique subject identifier (RID) and visit code (VISCODE), indicating the time of the visit (e.g. baseline, 6 month follow-up, etc.) TADPOLE, a dataset originally created for a data science challenge to forecast future biomarker measurements for individuals in the ADNI study, was also used as a base dataset.
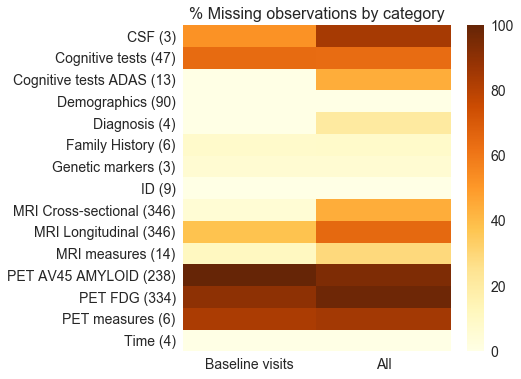
Several other datasets were merged onto the base datasets, such as ADAS cognitive assessment scores (ADASCORES), family history (FHQ), patient demographics (PTEMOG) and genetic markers (TOMM40). In most cases the datasets could be merged using the unique patient identifier and the visit code. Data processing was performed on the merged dataset to make it suitable for further analysis. The data types of all the variables were reviewed and converted to the correct format as required. Categorical variables were one-hot encoded with some grouping applied to levels with a small number of observations. A metadata file was created with descriptive information about each variable in the dataset. The figure below summarizes the number of predictors (shown in brackets) for each biomarker category in the data as well as the proportion of missing observations for each category.
Feature categories
Exploratory Data Analysis (EDA)
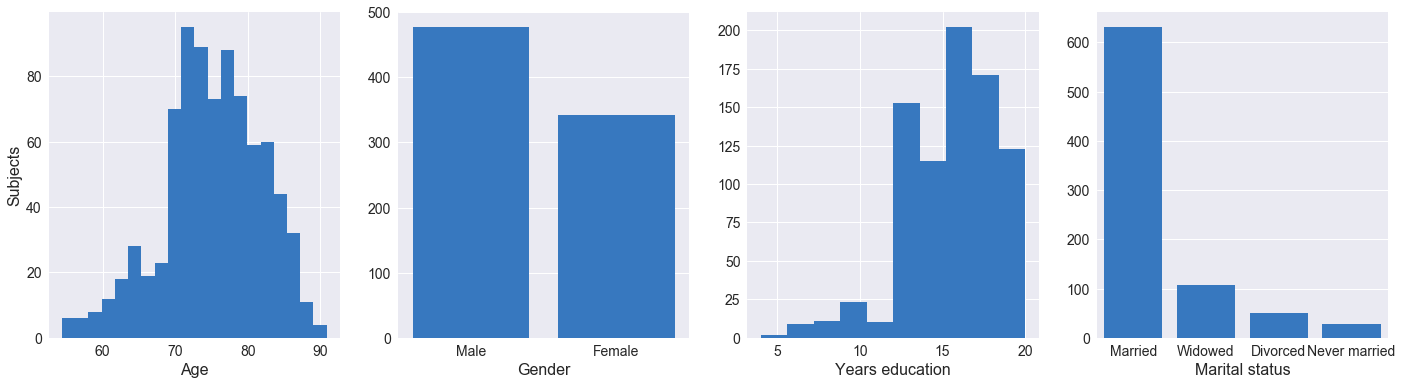
Our initial data exploration focused on demographics of the participants recruited for the ADNI I phase. As seen above, the majority of participants are married and range between ages 70 and 85, with no participants aged below 55 or above 90. The participants are majority white and male (~40% more males than females), and a significant proportion have some tertiary education. As mentioned on the ADNI website, the study is not population-based and enrolls selected populations who may be used in future treatment trials. The results from ADNI and therefore our analysis may not be generalizable to other populations.
Cognitive tests are an important measure in diagnosing Alzheimer’s disease, although signs of cognitive decline only become apparent when the disease is well progressed. The relationship between the scores for four cognitive tests and AD diagnosis are shown in the charts above.
- CDRSB (Clinical Dementia Rating Sum of Boxes), ADAS11 (Alzheimer’s Disease Assessment Scale–Cognitive subscale): average scores positively correlated with severity of cognitive impairment
- MMSE (Mini-Mental State Examination), RAVLT_immediate (Rey Auditory Verbal Learning): average scores negatively correlated with severity of cognitive impairment.
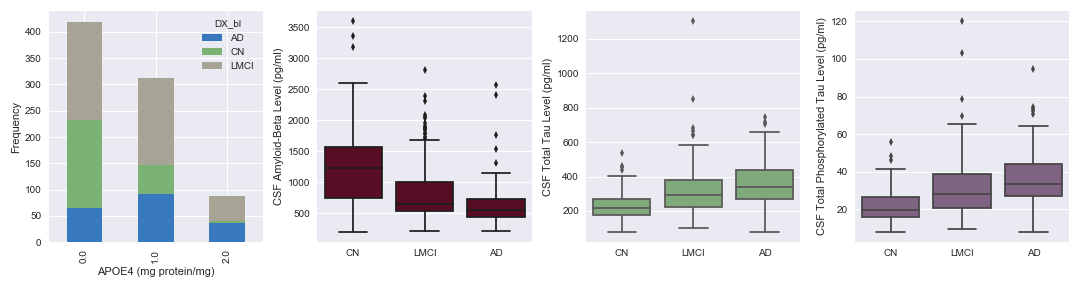
Protein APOE4 is a known risk factor for AD. In Fig. 3, we can see that the elevated protein levels are prevalent in LMCI and AD patients. Amyloid-Beta, Total Tau and Phosphorylated Total Tau are proteins in the cerebrospinal fluid, which past studies have shown to be associated with AD. From our visualization above, we observe that Amyloid-Beta levels are negatively correlated with AD progression, while the two latter proteins display a positive correlation with AD progression.
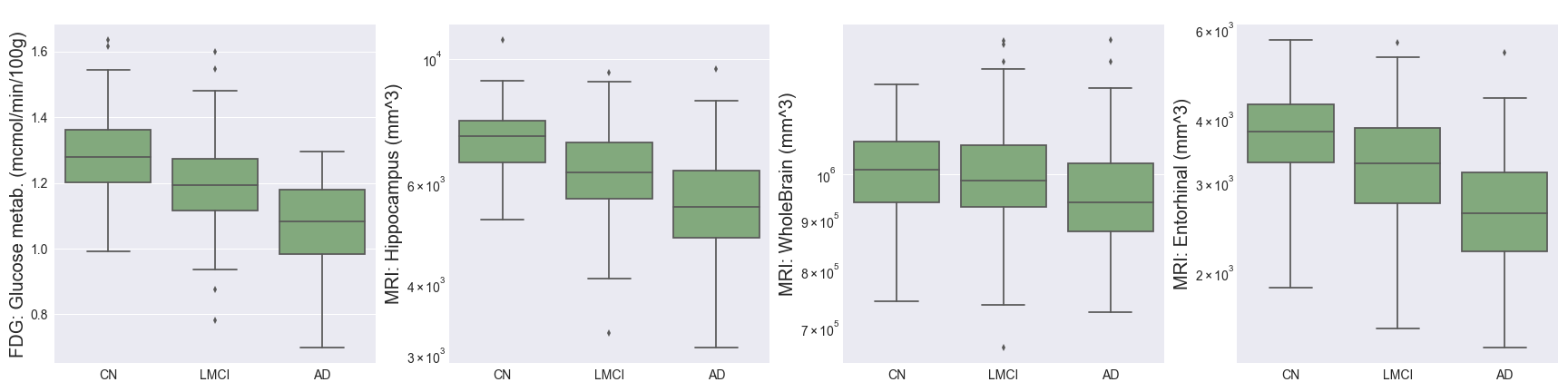
Imaging techniques such as MRI and PET measure important brain biomarkers and are used to help make AD diagnoses.
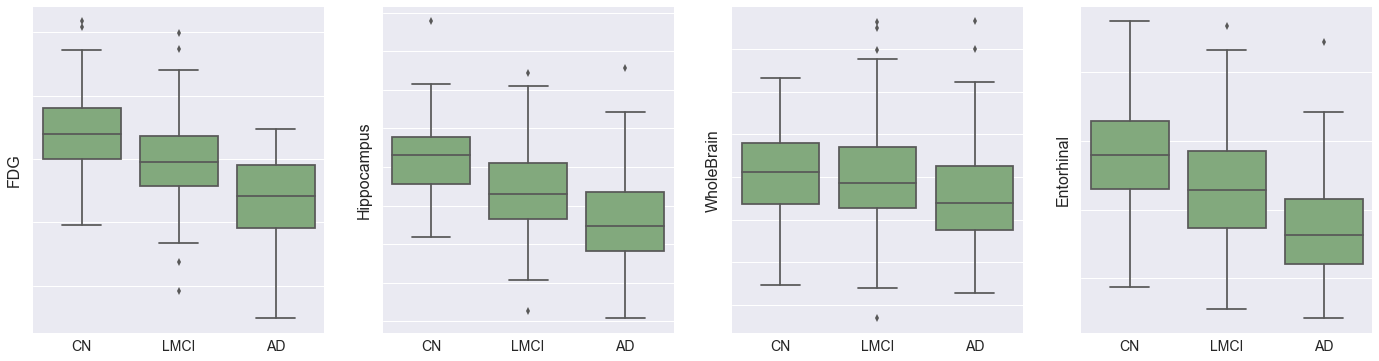
- Fluorodeoxyglucose (FDG) measures cell glucose metabolism and is an indicator of neurodegeneration, obtained from PET scans. We can see above that this decreases as AD progresses.
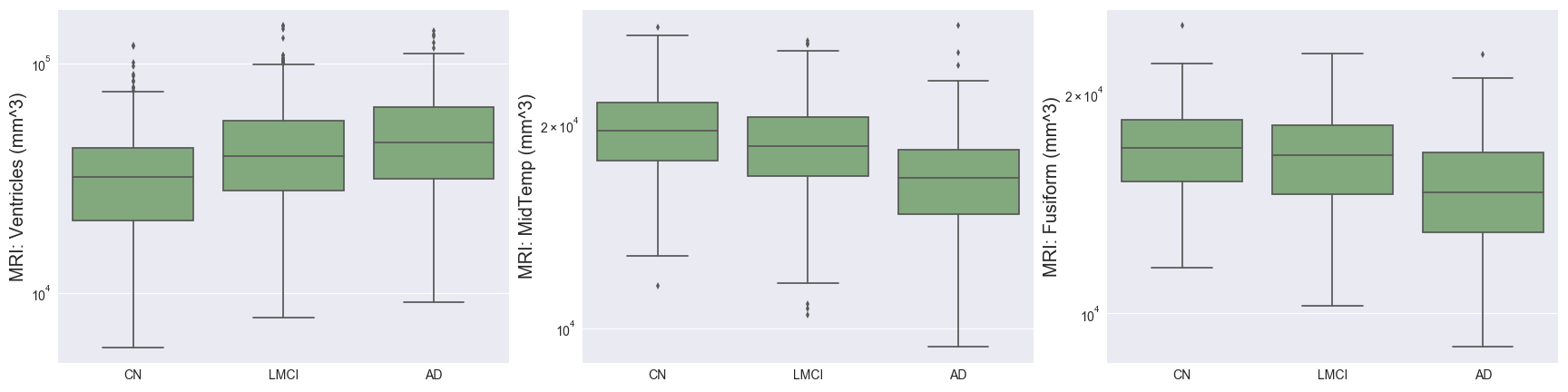
- Hippocampus, WholeBrain, Entorhinal, Fusiform, MidTemp, and Ventricles represent volumetric measures of different parts of the brain. The charts above support the hypothesis that AD progression is associated with brain atrophy, in addition to increased brain ventricular volume. The proportional decrease in average entorhinal volume with cognitive impairment is especially marked, and aligns with medical research showing that the entorhinal region is one of the first to be affected by AD.
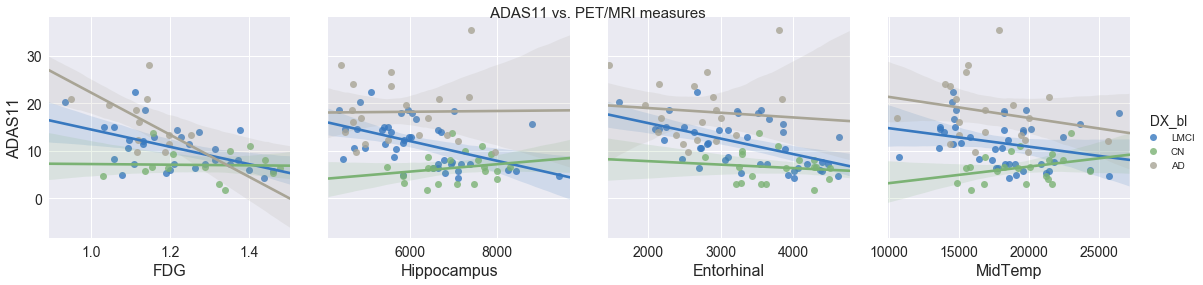
The ADAS11 cognitive test is collinear with some brain volumetric measures (Hippocampus, Entorhinal, MidTemp) and FDG, and therefore it may be possible to optimize for cost by substituting MRI for PET. Although PET scans are non-invasive and provide useful data, they are expensive and expose the patient to potentially harmful ionizing radiation.
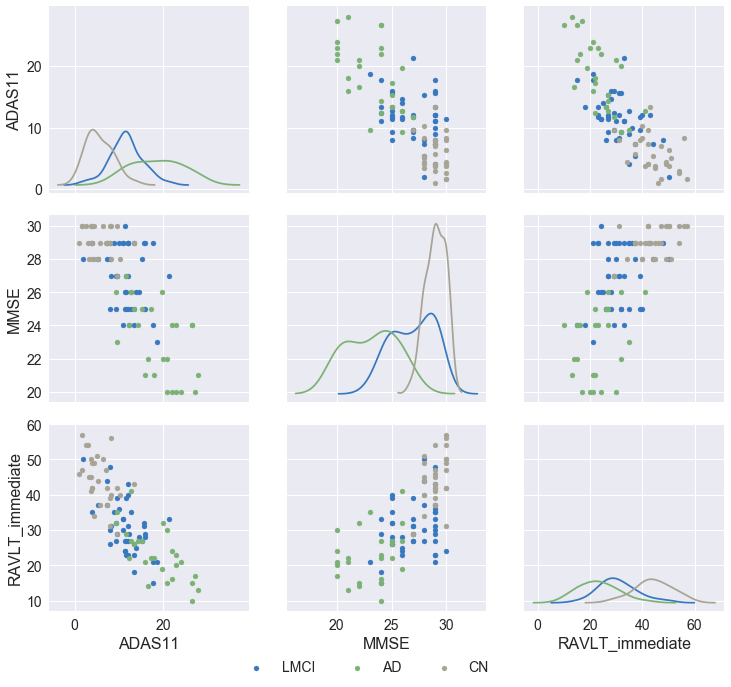
From the figure above, we see that the cognitive tests are correlated to a degree (looking at the relationship between ADAS11 & RAVLT, ADAS11 & MMSE as well as RAVLT & MMSE), allowing us to only pick the most time- and cost-effective test in our predictive model.